在上篇–理解 Cabbage 框架的基础设计一问中我们梳理了Cabbage的基本类结构。本篇主要分析相关细节实现。
体验繁琐
AVFoundation提供了一套很强大的api,但是使用起来却很繁琐。不体验AVFoundation的繁琐,就无法真正理解Cabbage的简单。短视频应用中,最常见的需求是,将用户选定的多个视频片段拼接在一起,然后播放。我们就通过一个小例子感受下AVFoundation。
1 | |
通过上面的代码,我们可以完成拼接工作。是不是有种感觉:并不是很麻烦啊?实际跑起来的时候,你会发现这效果并不是你想要的。比如:图像方向不对、填充模式不对、音乐声音无法控制。下面我们借助AVVideoComposition来修复这些问题
1 | |
这次实现的效果还是可以的,视频画面方向正确,位置居中,并且填充,声音在存在渐变。可以看到,满足这一小小需求就需要这么一大坨代码。要知道,这里还没有考虑其他的填充模式,没有考虑转场等等…
化繁为简
还是上面的需求,我们尝试用Cabbage来完成。
1 | |
哇卡卡,原来的一坨变成现在几行代码,简直不要太爽。那么接下来的任务就是扒开表层,深入内部,学习这种封装思想。
从表象开始
参考上面的代码,作为Cabbage的使用方来说,我们需要完成 3 个步骤:
- 准备资源
- 使用资源构造
Timeline - 把
Timeline塞到CompositionGenerator中进行加工
可以这样理解,前两步是数据的记录配置阶段,属于数据的产生;而最后一步通过配置获取结果,属于数据的消费。在理解 Cabbage 框架的基础设计中,我大致梳理了相关的类及其职责,那么通过深究CompositionGenerator的消费过程,可以使你更加明白。
深陷其中
CompositionGenerator提供的接口主要有三个:
public func buildPlayerItem() -> AVPlayerItem {}获取用于播放的播放条目public func buildImageGenerator() -> AVAssetImageGenerator {}获取用于生成快照的快照生成器public func buildExportSession(presetName: String) -> AVAssetExportSession? {}获取用于导出文件的导出器
而这三个过程又极其的相似:
- 生成
AVComposition - 生成
AVVideoComposition用于控制视频画面 - 生成
AVAudioMix用于混音(生成快照时不需要) - 使用上面的对象分别生成配置
AVPlayerItem、AVAssetImageGenerator以及AVAssetExportSession并返回。
如下:

自然,这里的重点就落在了如何生成前三步的对象了。
buildComposition
该阶段负责读取timeline中的资源,将其插入到AVMutableComposition合适的轨道中。这里主要分为 4 个步骤:
- 处理视频资源
- 处理音频资源
- 处理浮层(如贴纸)资源
- 处理额外的音频(如配音)资源
整体过程比较清晰,下面说下我认为需要注意点。
视频音频资源的轨道安排
视频资源和音频资源的轨道都使用了A/B轨模式(在两条轨道交叉放入各个资源的内容)。比如 3 个资源的轨道分布如下:
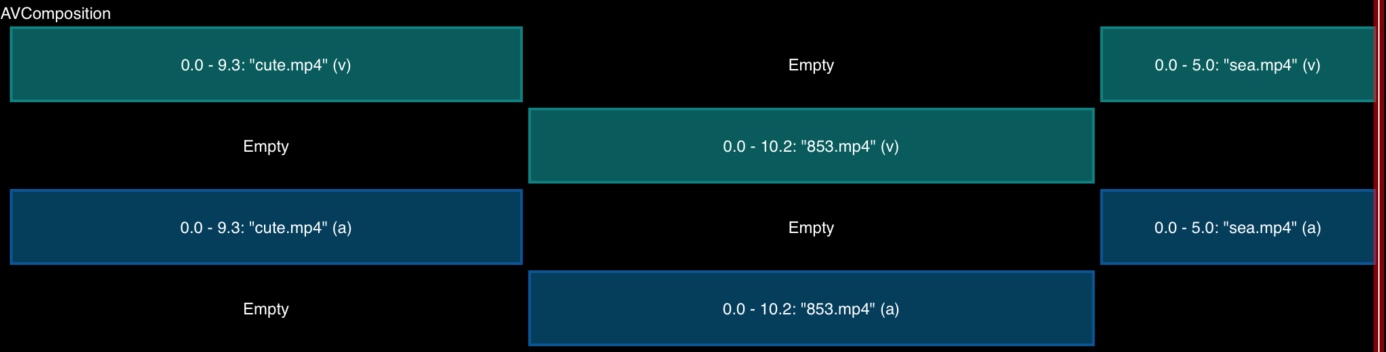
原因是,在AVMutableCompositionTrack中插入资源过程中,指定的时间点存在内容时,会根据该点将内容一分为二,后面的内容向后平移,新的内容插入。这个行为导致在一个轨道的同一个时间上无法同时存在两段内容,也就无法做类似转场的需求。所以A/B轨可以避开这个问题。
浮层内容的安排
为了节省资源,避免插入过多的轨道。在浮层的处理过程中,会尽力复用之前的轨道。但是,这里我找出了一个bug,导致最终复用的目的未达到。一起看代码吧,注释写的比较清楚:
1 | |
buildVideoComposition
该阶段,主要生成AVVideoComposition对象,对视频进行控制。分为 2 个主要步骤:
- 按时间段生成
instructions控制指令 - 使用自定义的视频混合器
instructions 控制指令
在buildComposition阶段,处理视频资源时,会记录轨道和资源集的映射,记录在mainVideoTrackInfo和overlayTrackInfo数组中。这里会遍历两个数组,生成VideoCompositionLayerInstruction数组。
得到VideoCompositionLayerInstruction数组后,经过排序,再按时间段分组。最终形成[time: [VideoCompositionLayerInstruction]]字典结构。每一个key-value组合将对应一个VideoCompositionInstruction。这样,就会得到控制指令数组。
视频混合器
视频混合器是自定义的VideoCompositor。在适当时机会收到系统回调,顺序是:
- 通过
renderContextChanged(_:)接收到渲染上下文 - 通过
startRequest(_:)接收异步的混合请求,处理完之后需要回调结构 - 通过
cancelAllPendingVideoCompositionRequests()接收取消事件
接下来,参考下面的类图,以及调用流程图,一起分析下具体的处理过程:
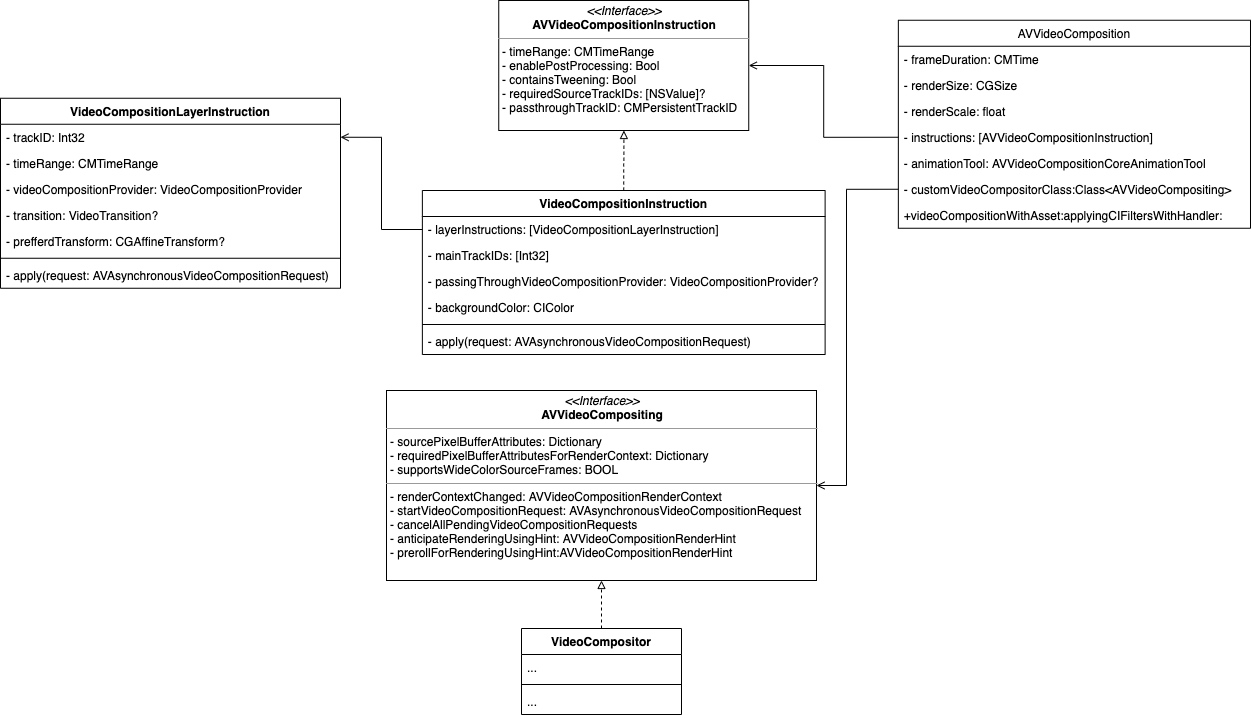
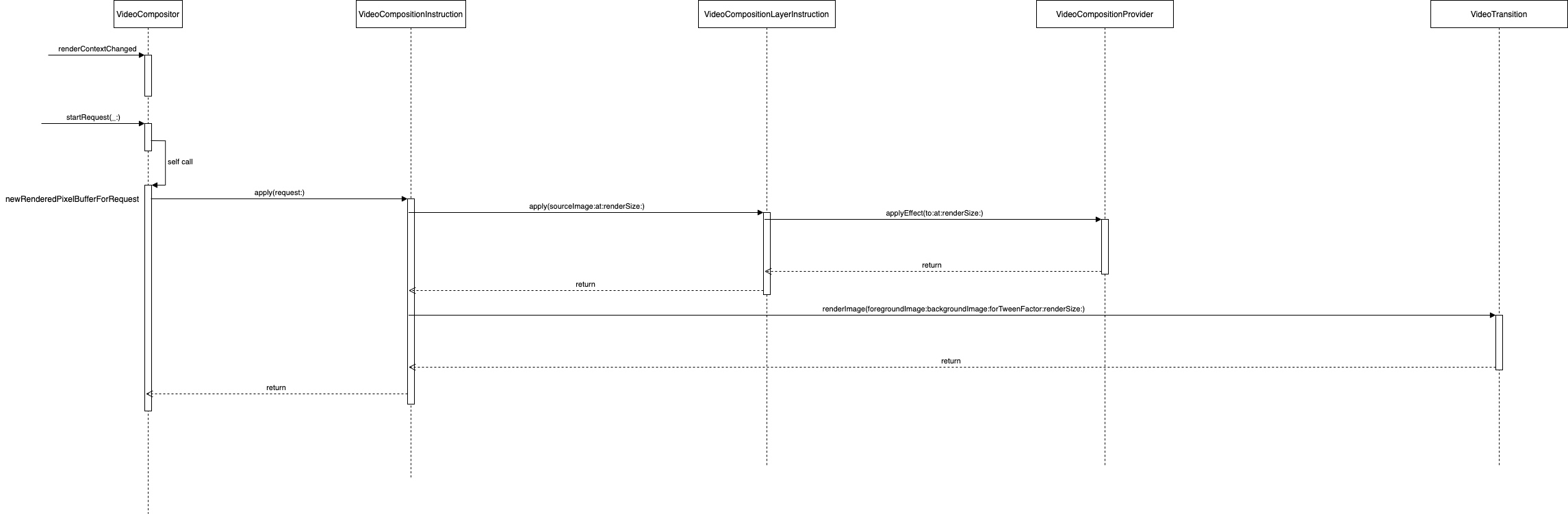
开始阶段。renderContextChanged(_:)将被调用,携带渲染上下参数,VideoCompositor只是记录,并没有多于操作。
接收混合请求。这个阶段是真正的混合阶段,牵扯到的方法较多,并且比较名称比较相似,具体可参考调用流程图的标注。重点是VideoCompositionInstruction中的apply(request:)方法:
1 | |
buildAudioMix
这个过程中,通过自定义AVAudioMixInputParameters的audioTapProcessor构建了音频混合器。整个过程在TrackItem的configure(audioMixParameters:)方法中实现,这是来自AudioMixProvider协议的方法:
1 | |
AVMutableAudioMixInputParameters的audioProcessingTapHolder属性是使用runtime添加的。在其setter方法中,audioTapProcessor属性得到真正的赋值。而最终自定义音频的处理,体现在AudioProcessingTapHolder中audioProcessingChain属性。AudioProcessingTapHolder在构建MTAudioProcessingTap是,会设置一个数据回调tapProcess,在回调中,会向外回调audioProcessingChain。
总结
总体来看,Cabbage的封装是成功的,它将大部分的固有流程都处理了,并将可定制化的接口都留出来了。但,通过一路的分析,我也感觉到该框架并没有达到其该有的形态,有些部分还是有点繁琐。下一篇中,我将谈谈自己的理解,并作出改进。
共勉!